Les échelles de satisfaction, largement utilisées en économie et dans les sciences sociales, reposent sur une hypothèse implicite forte : les répondants interprètent les écarts entre les valeurs de manière linéaire. Autrement dit, la différence de satisfaction représentée par l’écart entre deux points consécutifs de l’échelle (par exemple entre 6 et 7) serait équivalente à celle entre deux autres (entre 7 et 8). Cette hypothèse conditionne l’usage d’outils statistiques standards et, plus largement, l’interprétation des résultats empiriques.
Cette note examine la validité de cette hypothèse et ses conséquences. Nous développons d’abord une mesure synthétique du degré de non-linéarité dans l’utilisation des échelles de réponse. Nous montrons ensuite, à partir d’une série d’expériences menées auprès de plus de 1000 individus, que les échelles ne sont pas utilisées de manière parfaitement linéaire. Toutefois, ces déformations restent en moyenne modestes.
Enfin, nous évaluons les implications de ces non-linéarités pour les résultats empiriques produits par la recherche en mobilisant une large base de données d’estimations issues de la littérature. Si des transformations extrêmes peuvent fortement modifier les conclusions (signe et significativité des coefficients), les déformations plausibles ont des effets plus limités sur ces dimensions. En revanche, elles peuvent affecter de manière substantielle l’ampleur des effets estimés, notamment dans les analyses visant à exprimer les résultats en équivalent monétaire.
Ces résultats suggèrent que l’hypothèse de linéarité constitue souvent une approximation raisonnable pour l’identification qualitative des effets, mais qu’elle peut être plus problématique pour leur interprétation quantitative. Nous plaidons ainsi pour une pratique systématique d’analyses de sensibilité aux non-linéarités, afin de renforcer la crédibilité et la transparence des travaux empiriques fondés sur des données subjectives. Nous proposons également une méthode pour le faire.
Anthony Lepinteur, University of Luxembourg
Les enquêtes occupent aujourd’hui une place centrale dans l’analyse économique et sociale. Elles permettent de mesurer des phénomènes difficiles à observer directement, comme le bien-être, la satisfaction ou les attitudes, à l’aide de questions simples :
« Sur une échelle de 0 à 10, à quel point êtes-vous satisfait de votre vie ? »
Ces échelles numériques sont omniprésentes, aussi bien dans la recherche académique que dans la production d’indicateurs destinés à éclairer les politiques publiques.
L’utilisation de ces données repose toutefois sur des hypothèses concernant l’interprétation que font les enquêtés des échelles proposées. En première intention, les chercheurs supposent souvent que l’échelle est comprise comme une mesure cardinale, linéaire, avec des écarts constants entre les échelons. Autrement dit, la différence entre 6 et 7 serait équivalente à celle entre 7 et 8 du point de vue des répondants. Cette hypothèse permet d’utiliser des outils statistiques simples et largement diffusés (même si les chercheurs vérifient souvent la solidité des résultats à l’aide d’autres modélisations).
Mais cette hypothèse est-elle réaliste ? Les individus perçoivent-ils réellement les échelles de manière uniforme ? Et, si ce n’est pas le cas, quelles en sont les conséquences pour les résultats empiriques ? Deux intuitions opposées peuvent être formulées. D’un côté, on peut penser que les individus utilisent les échelles de manière approximativement régulière, ce qui justifierait les pratiques empiriques standard. De l’autre, il est plausible que certaines valeurs aient une signification particulière (par exemple les extrêmes ou le milieu de l’échelle), ce qui introduirait des non-linéarités dans les réponses.
Un article de Timothy Bond et Kevin Lang (Bond and Lang 2019), attaquait de façon très virulente l’hypothèse de linéarité, remettant en cause de nombreux résultats établis par la recherche en économie du bonheur et du bien-être subjectif.
Pour en avoir le cœur net, nous avons entrepris d’examiner cette question de manière systématique (Kaiser and Lepinteur 2025). Cette note rend compte de notre analyse.
Notre méthode pour répondre à la question
Notre première contribution consiste à développer un cadre permettant de mesurer les écarts à l’hypothèse de linéarité dans l’utilisation des échelles de réponse.
Le point de départ consiste à envisager sérieusement le point de vue (destructeur) de Bond et Lang, selon lequel les réponses ne sont pas directement comparables, mais résultent de la transformation potentiellement non linéaire d’une variable latente (par exemple le bien-être ressenti). Certaines parties de l’échelle peuvent ainsi être « comprimées » et d’autres « étirées », selon la manière dont les individus perçoivent les différences entre les valeurs. Par exemple, il faudrait peut-être un saut de bonheur latent plus important pour qu’un individu passe de 9 à 10 plutôt que de 5 à 6, sur l’échelle de bonheur.
Pour quantifier cette possibilité, nous proposons une mesure de non-linéarité fondée sur une approche axiomatique. Nous définissons un petit nombre de propriétés simples et naturelles que devrait satisfaire toute mesure pertinente (par exemple : être nulle lorsque l’échelle est parfaitement linéaire, et augmenter lorsque les déformations deviennent plus importantes).
Cette démarche est analogue à celle utilisée pour mesurer les inégalités de revenu. De la même manière que le coefficient de Gini résume en un seul indicateur la dispersion d’une distribution de revenus, notre mesure résume en un chiffre le degré de non-linéarité d’une échelle de réponse.
Cet indice est compris entre 0 et 1 :
- il vaut 0 lorsque l’échelle est parfaitement linéaire ;
- il se rapproche de 1 dans les cas de non-linéarité extrême, par exemple lorsqu’on réduit l’échelle à une simple opposition entre deux catégories (une forme de dichotomisation).
Grâce à cette méthode, nous pouvons ainsi attribuer une valeur numérique au degré de non-linéarité des échelles de réponse.
La question est alors de savoir quel est, empiriquement, le niveau de non-linéarité. Autrement dit, dans quelle mesure les individus s’écartent-ils réellement de la linéarité lorsqu’ils répondent à ces questions ? Pour le savoir, nous avons mis en place une approche expérimentale.
Application expérimentale
Notre deuxième contribution, de nature expérimentale, repose sur une série d’expériences spécifiquement conçues pour mesurer la manière dont les individus perçoivent les distances entre les différentes valeurs d’une échelle, au moyen d’une enquête en ligne auprès de plus de 1000 participants au Royaume-Uni. Parmi les différentes expériences, l’une demande directement aux participants d’évaluer les écarts de bien-être ressentis correspondant aux échelons. Cette approche permet de reconstruire empiriquement la « géométrie » de l’échelle telle qu’elle est perçue.
Nous demandons également à une moitié de l’échantillon (choisie aléatoirement) de déclarer leur satisfaction dans la vie en considérant l’échelle comme linéaire. L’autre moitié de l’échantillon doit simplement déclarer sa satisfaction dans la vie, sans aucune autre instruction. L’objectif est de comparer la mesure dans laquelle un niveau de satisfaction recueilli de manière « classique » (c’est-à-dire sans instruction particulière) diffère d’un niveau de satisfaction sous l’hypothèse de l’échelle linéaire.
Quelle que soit l’approche retenue, au-delà de ces deux exemples, nos résultats, montrent clairement que l’utilisation des échelles n’est pas parfaitement linéaire. Certaines zones de l’échelle — en particulier les extrêmes — sont perçues de manière différente des autres. Par exemple, pour certains individus, la différence de bonheur latent correspondant aux échelons 9 et 10 peut être jugée plus forte (ou plus faible) qu’entre les échelons 5 et 6.
Cependant, de fait, ces non-linéarités restent globalement modérées. En moyenne, l’indice de non-linéarité est égal à 0,10 – ce qui correspond à une déviation modeste par rapport à l’hypothèse de linéarité.
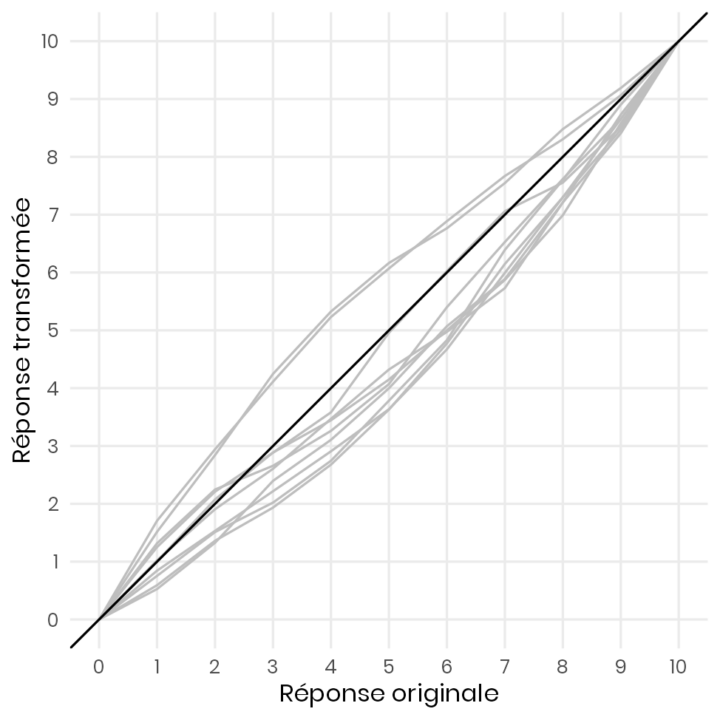
Afin de donner un ordre de grandeur, la Figure 1 ci-dessous montre à quoi correspond une non-linéarité de 0,10. L’axe des abscisses représente les catégories de satisfaction de vie sur une échelle de 0 à 10, tandis que l’axe des ordonnées indique les valeurs numériques de bien-être latent ressenti associées à ces catégories. La droite à 45 degrés correspond à la linéarité, et les courbes en gris illustrent différentes manières dont les individus utilisent les échelles en moyenne, ce qui correspond à un niveau de non-linéarité de 0,10.
Passage au crible des principaux résultats de la recherche empirique sur le bien-être subjectif
La troisième contribution consiste à évaluer les conséquences pratiques de ces non-linéarités pour la recherche empirique.
Pour cela, nous avons créé une base qui regroupe un grand nombre d’estimations issues de la littérature sur le bien-être subjectif. Nous reproduisons plus de 40 000 estimations provenant de plus de 70 articles publiés dans les principales revues d’économie, et nous réestimons ces relations en introduisant différentes formes de non-linéarité.
| Risque de changement de signe | |
| N’importe quelle déviation | 61 % |
| Déviations plausibles | 18 % |
| Risque de perte de significativité | |
| N’importe quelle déviation | 22 % |
| Déviations plausibles | 10 % |
Risque de changement de signe ou de signiificativité selon que les déviations sont seulement plausibles, ou possibles (non-linéarité < 0,10).
Le tableau 1 ci-dessus présente le risque que les coefficients estimés dans ces articles changent de signe ou de significativité statistique lorsque l’on relâche l’hypothèse de linéarité. Chaque pourcentage indique la part des estimations concernées par ces inversions, selon que l’on considère toutes les déviations de linéarité possibles de l’échelle ou seulement celles jugées plausibles c’est-à-dire compatibles avec les niveaux de non-linéarité mesurés dans nos expériences (niveau de non-linéarité inférieur ou égal à 0,10).
Des relations empiriques validées
Le tableau 1 met en évidence un résultat important : lorsque l’on autorise n’importe quelle forme de non-linéarité, les risques de renversement sont élevés. Plus de 60 % des coefficients peuvent changer de signe et plus de 20 % ne sont plus significativement différents de zéros a des niveaux conventionnels.
En revanche, lorsque l’on se limite aux transformations plausibles, ces risques diminuent fortement. Les inversions de signe deviennent rares, et les pertes de significativité plus limitées. Mais des ordres de grandeur moins certains
Au-delà de ces risques liés au signe et la significativité, il reste une question importante : qu’en est-il de la stabilité de l’ampleur des effets estimés ?
Les mesures de bien-être subjectif sont de plus en plus utilisées, notamment dans le cadre des analyses coûts-bénéfices, où elles permettent de comparer des politiques très différentes à l’aide d’une unité commune.
Dans ce contexte, les chercheurs s’intéressent souvent au rapport entre les coefficients associés au revenu et à d’autres variables, afin d’exprimer les effets en équivalent monétaire. Par exemple, le ratio entre les coefficients du chômage et du revenu permet d’estimer le montant de revenu nécessaire pour compenser la perte de bien-être liée au chômage.
Pour analyser la robustesse de ces évaluations, nous nous concentrons sur les articles de la base WellBase dans lesquels le revenu et le chômage apparaissent simultanément dans les régressions de bien-être. Nous recalculons ensuite le ratio des coefficients en introduisant différentes transformations non linéaires de l’échelle, en particulier celles compatibles avec les niveaux de non-linéarité mesurés dans notre expérience.
Les résultats montrent que, même pour des déformations plausibles, ces équivalents monétaires peuvent varier de manière substantielle. Autrement dit, l’évaluation du coût du chômage en termes de bien-être dépend sensiblement de la manière dont les individus utilisent les échelles de réponse. Ces résultats soulignent que, si les analyses en bien-être subjectif constituent un outil puissant pour l’évaluation des politiques publiques, leur interprétation quantitative – en particulier en termes de conversion des effets en termes monétaires – peut être sensible aux hypothèses de mesure.
Conclusion : un nouvel outil de validation des analyses
Les enquêtes restent un outil indispensable pour comprendre le bien-être subjectif. Elles permettent d’accéder à des dimensions de la vie économique et sociale qui ne sont pas observables autrement.
Cependant, notre étude montre que la manière dont les individus utilisent les échelles de réponse mérite une attention particulière. À mesure que ces données sont de plus en plus utilisées pour orienter les politiques publiques, la question de leur interprétation devient centrale.
Faut-il corriger systématiquement les non-linéarités de l’échelle de satisfaction ? Ou bien considérer que l’hypothèse de linéarité fournit une approximation suffisante pour de nombreuses applications ? Ces questions restent ouvertes.
Dans ce contexte, nous proposons plusieurs pistes pour la recherche future. Une approche simple consiste à évaluer systématiquement la robustesse des résultats à des déviations plausibles de linéarité. Concrètement, les chercheurs peuvent utiliser les outils que nous mettons à disposition (notamment sous forme de commandes Stata) pour mesurer dans quelle mesure les signes, la significativité et la magnitude des coefficients varient lorsque l’on relâche l’hypothèse de linéarité.
Faire état de ces analyses de sensibilité permettrait de mieux apprécier la solidité des résultats empiriques et d’en faciliter l’interprétation, en particulier dans les applications où la taille des effets joue un rôle central.
Ces recommandations ne concernent pas uniquement les mesures de bien-être subjectif. Elles s’appliquent plus largement à l’ensemble des échelles de type Likert, largement utilisées en économie et dans les sciences sociales.
Elles invitent à adopter une pratique simple : ne plus considérer la linéarité comme acquise, mais comme une hypothèse testable. À ce titre, documenter systématiquement la sensibilité des résultats à des déviations plausibles de linéarité constitue une étape naturelle pour renforcer la crédibilité des analyses empiriques.
Bibliographie
Bond, Timothy N, and Kevin Lang. 2019. “The Sad Truth about Happiness Scales.”Journal of Political Economy 127 (4): 1629–40. https://doi.org/10.1086/701679.
Kaiser, Caspar, and Anthony Lepinteur. 2025. “Measuring the Unmeasurable? Systematic Evidence on Scale Transformations in Subjective Survey Data.” Working paper 3gmzy_v1. Center for Open Science. https://doi.org/10.31219/osf.io/3gmzy_v1.